

Agil soll sie sein, die Supply Chain. Robust und resilient. Vorausschauend auf mögliche Risiken reagieren, potenzielle Probleme frühzeitig erkennen und diese flexibel umschiffen.
Dafür bedarf es der intelligenten Nutzung von Daten. Aber wie werden Daten wirklich „smart“?
Hindernis 1: Datenprobleme allerorten
Ein Blick auf den typischen Supply-Chain-Prozess offenbart uns zunächst einmal keine „smarten“ Daten, sondern vielmehr etliche Datenprobleme. Meist liegen die Daten in unzähligen Silos verborgen – im ERP-System, in diversen SaaS-Lösungen oder gar in Systemen, auf die wir überhaupt keinen Zugriff haben. Kurzum: Die Daten liegen über viele Bereiche verstreut mit jeweils unterschiedlichen Datenhoheiten.
Doch die Daten sind nicht nur über verschiedene technische Systeme verteilt, sondern auch inhaltlich stark fragmentiert. Manche befinden sich im Bereich des Lieferantenmanagements, andere im Supply Chain Management und wieder andere im Transportmanagement.
Hinzu kommt ein Mangel an Echtzeitinformationen. Der Datenaustausch zwischen den Kollaborationspartnern geschieht meist asynchron in größeren Zeitabständen.
Und schließlich fehlt eine Datenharmonisierung. So kämpfen wir beispielsweise mit unterschiedlichen Materialnummern für ein und dasselbe Gut entlang der Lieferkette. Das Gleiche gilt etwa für Komponentennummern.
Hindernis 2: Vorwärts fahren, rückwärts schauen – mit blindem Rückspiegel
Damit ist ein ganzheitlicher Blick auf alle Daten in den Supply-Chain-Prozessen nahezu unmöglich. Ganz zu schweigen von einem proaktiven Management bei auftretenden Problemen. Und während des Supply-Chain-Prozesses können durchaus eine Menge Probleme auftreten: Das fängt schon bei der Bestellung an. Manche Zulieferer bestätigen diese gar nicht, andere mit völlig anderen Liefermengen oder Lieferfristen. Auch kennen viele Unternehmen gar nicht die Kapazitätsgrenzen ihrer Lieferanten und fragen etwa deutlich höhere Stückzahlen an als diese produzieren können.

Während des nächsten Prozessschrittes – der eigentlichen Produktion – sind die Auftrag gebenden Unternehmen dann völlig blind. Das Problem: Dieser Prozessschritt dauert in der Fertigungsindustrie teils viele Wochen bis Monate.
Erst mit der Erstellung des Lieferavis, erhalten die Unternehmen wieder einen Einblick in die Prozesse – sofern die Lieferanten denn einen Lieferavis ausstellen. Häufig weicht dieser jedoch von der ursprünglichen Bestellung ab. Für den Kunden eine unangenehme Überraschung. Und vor allem eine Überraschung, bei der er kaum noch Zeit hat zu reagieren.
Und so ziehen sich die möglichen Probleme noch weiter durch: Von verspäteten, verloren gegangenen oder beschädigten Transporte über Unklarheiten beim Wareneingang bis hin zu Fehlern bei der elektronischen Rechnung.
Selbst das beste Reporting oder der Einsatz von klassischer Business Intelligence helfen hier nicht wirklich weiter. Denn diese schauen nicht in die Zukunft, sondern dokumentieren lediglich die Probleme in der Vergangenheit. Wie ein Blick in den Rückspiegel. Und selbst in diesem Rückspiegel sehen wir häufig nur einzelne Puzzleteile: Einige Teile fehlen komplett, bei anderen fehlen zumindest die Verbindungsstücke – es ist also völlig unklar, wie diese zusammenhängen.
Wenn aber immer nur die einzelnen Prozessschritte separat analysiert werden können, ist Ursachenforschung und -behebung kaum möglich. Das gilt umso mehr, wenn dabei Prozessschritte komplett fehlen und die Daten auch nur in größeren Intervallen einfließen.
Doch wie lässt sich nun aus einzelnen Puzzleteilen ein großes, zusammenhängendes und vollständiges Bild erzeugen? Ein Bild, das sich in Echtzeit aktualisiert und erweitert? Ein Bild, das nach vorne schaut statt zurück?
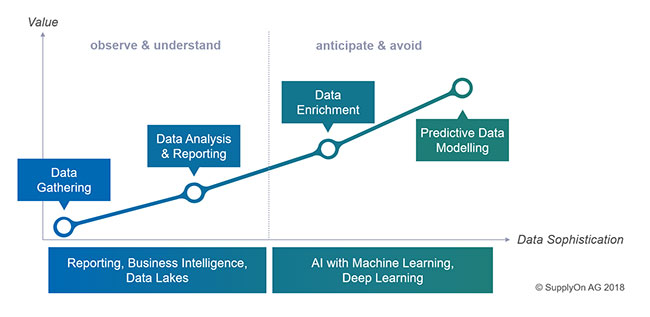
Lösung 1. Teil: Die Daten anreichern
Das geht nur durch Datenanreicherung. Wir müssen Daten in ihrem Kontext analysieren und dazu müssen wir Datenquellen anzapfen, die uns weitere Zusatzinformationen zu unseren Daten liefern können.
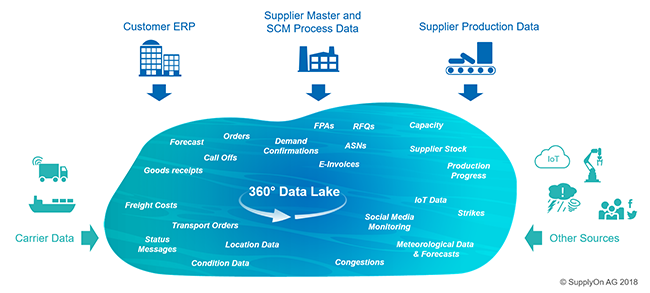
Konkret heißt das: In einen so genannten Data Lake fließen Informationen aus verschiedensten Quellen ein. Dazu zählen zunächst die Daten von Kundenseite, die zumeist noch in deren ERP-Systemen gespeichert sind. Dies sind beispielsweise Forecasts, Bestellinformationen, Lieferabrufe oder Wareneingangsinformationen.
Daneben speisen verschiedene Informationen von der Lieferantenseite den Data Lake, wie etwa Stammdaten, Daten aus dem Logistikbereich (Bestellbestätigung, Transportavis [Forwarder Pickup Advice, FPA], Lieferavis etc.) oder Angebotsanfragen (RFQ).
Hinzu kommen noch Informationen aus dem Transportmanagementsystem. Dies sind klassischerweise Statusmeldungen wie On-Time Delivery (ODT), Estimated Time of Arrival (ETA) und die Transportnummer. Darüber hinaus können wir heutzutage noch detailliertere Transportinformationen integrieren, wie die genauen Standortdaten, Informationen über den Zustand der transportierten Güter oder auch die Frachtkosten selbst.
Jenseits dieser mehr oder weniger klassischeren Informationen können wir mit Hilfe von APIs noch aus einer Fülle weiterer Daten schöpfen. Ganz zentral dabei: Informationen über den Produktionsprozess beim Lieferanten. Dessen Kapazitäten, Lagerbestände, Produktionsbeginn, -fortschritt und Mengenausstoß liefern uns wichtige Daten, um den bislang blinden Flecken zu beheben und frühzeitig eventuelle Planungsfehler auf Lieferantenseite zu bemerken.
Doch es existiert noch eine Reihe weiterer relevanter Informationen. Dazu zählen beispielsweise IoT-Sensordaten, Risikoinformationen über Streiks, politische Situationen oder auch Wetterdaten, die möglicherweise unsere Transporte auf bestimmten Routen beeinträchtigen können. Und schließlich ist auch Social Media eine wertvolle Daten-Fundgrube, aus der wir weitere wertvolle Erkenntnisse über Supply-Chain-relevante Ereignisse erhalten können.
Lösung 2. Teil: Den Daten Intelligenz einhauchen
All diese Daten liefern uns viele wichtige Puzzleteile, aus denen wir dann ein vollständiges Bild zusammensetzen und in die Zukunft schauen können. Dafür braucht es allerdings noch intelligenter Modelle auf Basis der Daten – sprich: Predictive Analytics.
Künstliche Intelligenz auf Basis von Machine Learning, Deep Learning oder anderen Ansätzen ermöglicht es dann, eine völlig neue Stufe an Datenqualität zu erreichen und somit auch zukünftige Probleme frühzeitig zu antizipieren. Oder anders gesagt: Tatsächlich Smart Data zu erhalten.


